Communication is hard. Like, really hard. Brain-to-brain state transfer is impossible, so we rely on an untold number of tools, signals, assumptions, wild guesses, and luck in the hopes that we can get someone else’s black box to generate something vaguely similar enough to our original for practical purposes. (And the bastards usually don’t even have the common courtesy to echo it back so we can see if we did it right.) What strikes me about “splaining†is that it’s so widespread–both the ostensible act and the complaints about it–and so consistent. Two reasonably distinct groups of individuals speaking on arbitrary topics, but the interactions generally resemble the same form and end up in the same place. While it would flatter me greatly if the vast majority of the people in my out-group turned out to be malicious and/or stupid, it seems more reasonable to conclude the groups communicate differently and as a result have a difficult time communicating with each other.
An interesting take on a social media phenomenon. This is well worth your time.
I suspect that a large part of the problem with “splaining†and other communication failures on Twitter and elsewhere is that we lose much of the metadata of conversation. To borrow Alice’s example, you can tell from tone of voice and mannerisms what someone means when they say “Get the fuck out of here!†to you. In a textual environment, we have to draw inferences from our relationship to this person and our previous encounters with them.
Even among nerds who value information sharing over other forms of communication, we still need some conversational metadata to fully divine meaning. A “Get the fuck out of here!†@-reply could be positive engagement, or it could be a threat. It’s possible to know this with clarity, but the nature of the medium makes it harder. And with a “rando,†it becomes harder still.
Alice also writes a great footnote on Twitter mentions, and what “public†actually means online. It’s 323 words that could be a standalone essay of their own. One problem, of sorts, with Twitter, is that we all use it differently. For some of us, it’s a salon, for others, it’s a megaphone. I think the average Twitter user is somewhere between the two. It would behoove Twitter to keep this in mind, and adjust the platform to give users a more granular degree of access from the world-at-large, rather than the binary options of “public†and “privateâ€.
I won’t take back some of the awful things about the Health app in iOS. It’s a clunky, poorly designed app that either needs a UI overhaul, or be hidden so that other apps can use its storage and synchronization APIs without taunting users into opening it. Still, with Apple Watch and apps that take full advantage of HealthKit, fitness tracking on iOS has improved a lot in the last year. The only place it falls down is that it’s easy to get data into Health, but very hard to get it out for whatever you want to accomplish with it.
I’d love a way to get a quick glance at my personal health data, especially historically. Health app sucks for this, and the individual apps that feed data into HealthKit are all fractured. MyFitnessPal is a great food tracker, and a miserable experience for exercise tracking. The Apple Activity app is great, but doesn’t sync with anything but Health. My preferred fitness dashboard, Fitport is good for a picture of your day so far, but does nothing for historical data. Piping all my hot, fresh fitness data into another service, like, say, Jawbone, is a world of hurt. I need another solution.
Many moons ago, I used Brett Terpstra’s Slogger to pipe my FitBit data into the awesome Day One journaling app. When I gave up on / lost my second FitBit, I gave up on saving that data. Slogger is cool, but it’s also a pain in the ass to set up, and won’t get data out of Health, anyway. That lives on my iPhone, not anywhere Slogger can get at it. So, my fitness data languished.
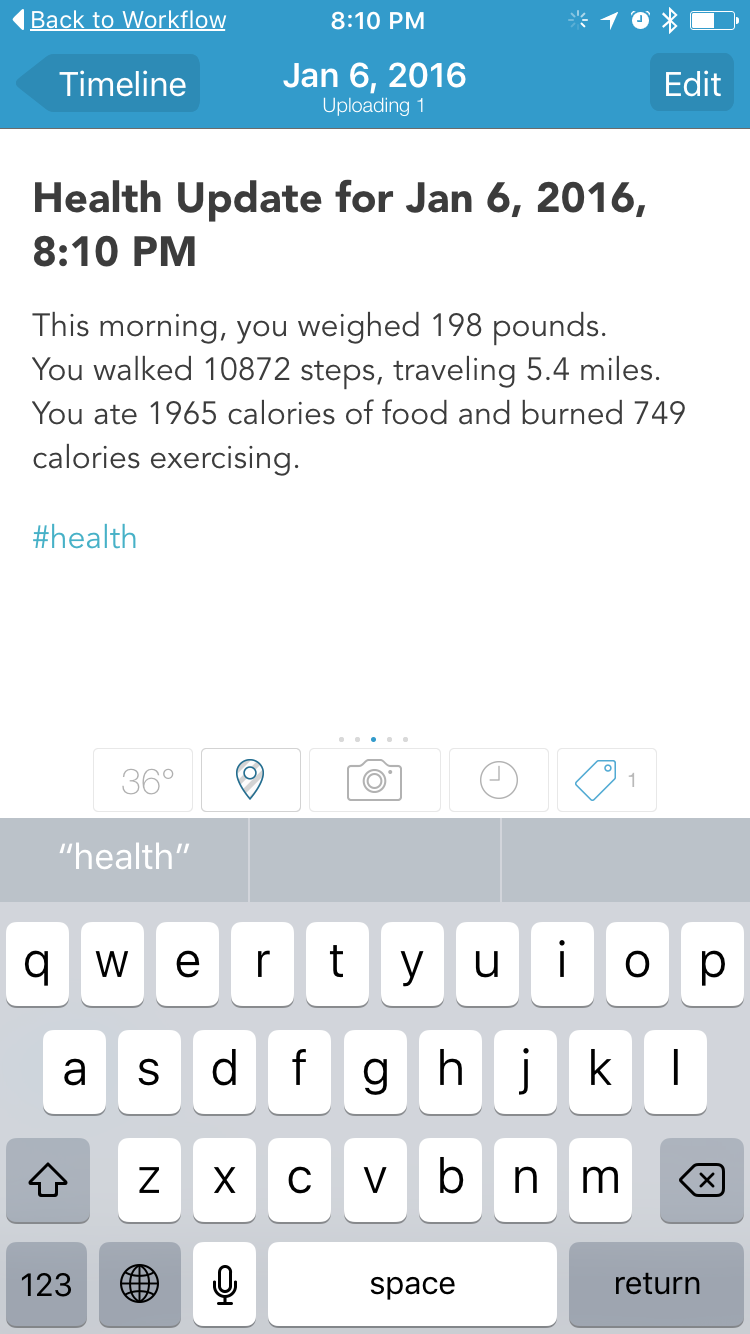
Workflow recently added support for HealthKit, both to save data to it, and pull data from it. What if I used Workflow to pull relevant data from Health, format it nicely, and stick it in a Day One entry with a hashtag to sort it out? It took some finagling, but I finally got something that works. Here’s what it looks like when it’s done:
Okay, not fancy. No charts or graphs, but it’s a succinct picture of my day, with all the metrics I’m tracking as I try and drop about thirty pounds or so. I could get way more detailed, and track macronutrients, but I don’t care about that. I’m just making sure I burn more than I consume, and making sure the big number trends downward.
If you want to use this yourself, or tweak it for your needs, you can find the workflow here. I have the Workflow saved as an action in Launch Center Pro, with a push notification scheduled for 9:30 PM each day, which is also when I get reminded to do my daily journaling.
Hopefully, future versions of Workflow add support for getting the amount of time spent working out, and maybe access to sleep data, so I can get a bigger picture. Either way, what I have is a good, simple start for taking control of my data and seeing what I’ve been doing. Or, I suppose, not doing, if I ever fall off the wagon.
If you haven’t read or watched “The Website Obesity Crisis†by Maciej Cegłowski, you really should. It’s one of the smartest things said or written about the state of the Web today. It’ll also help you get some context for the essay to follow. So, go click that link. I’ll be here when you’re done.
Okay, are you back? Great. Now, let me cite one of Maciej’s concluding parts.
Let’s preserve the web as the hypertext medium it is, the only thing of its kind in the world, and not turn it into another medium for consumption, like we have so many examples of already.
There’s a lot to unpack here. I know where Maciej is coming from. I work in digital publishing, I’ve been making stuff on the web for nearly twenty years, and I am trying to teach myself modern front-end development. The Web in 2016 is very different than the Web of 1996, which when I first got online. I learned the basics of building websites that same year, out of a copy of HTML for Dummies: Quick Reference. You could, at the time, make something throughly awesome by going to “View Source†on any website on the Internet copying, pasting, and fiddling with the code.
Now? Well, have you ever tried viewing the source on Google.com? I did once, and I when I came to, I was naked and covered in what I hoped was my own blood. Web development is hard, things are bloated, and the sense of independence and fun of making stuff on the web is largely gone. It’s been replaced by blue and white faux-minimalism that grinds your computer to a halt to load ads. It’s no fun.
Making anything cool now, well, it takes a lot more work and knowledge than it did in 1996. Even if you’re just building the theme for a blog, you need to know a lot more to make things look awesome everywhere. And awesome looking stuff takes a lot more computing power to render. So…
Let’s commit to the idea that as computers get faster, and as networks get faster, the web should also get faster.
Here’s the screwy bit. Aside from a period when mobile devices that could view the real Web were just taking off—basically with the original iPhone—computers, networks, and the web are all getting faster. It’s just that once things get fast enough that we get even the slightest bit of overhead, web stuff gets more complex and demanding on the network and the computer. Just look at the development of JavaScript interpreters in browsers. There’s an arms race to optimize how fast a browser handles JavaScript, and it has had a performance impact for the better.
It’s not even a new problem. The move to semantic markup and CSS was actually supposed to speed the Web up for users. You might have to download another page, but your browser kept the CSS file and images cached. Pages loaded faster, and rendered faster, at least as your computer got faster. Then, with all that freed up computing power, web people decided to try crazier stuff. And things got more complicated and slower to load. Either the technology catches up (broadband), or we start stripping stuff down again (early Web 2.0). It’s cyclical.
There was a period in the 90s when computers completely revolutionized print typography and design. People were making, and publishing really wild stuff, but it was a fad. There was eventual pushback over crazy neon colors, hard-to-read fonts, and screwy layouts that looked insanely cool, but made reading print a huge pain in the butt. If looking at those examples reminds you of the late 90s on the web, you’re not far off. That aesthetic carried over to many websites, too. I dare you to look at wired.com circa 2000 on the Internet Archive.
Fortunately, that cycle is moving towards simplification again. The pushback on bloated ads, tracking scripts, and all the excessive crap that spins up our laptop fans and pushes us over the data limits on our mobile plans is reaching a head. Soon, we’re going to have a reckoning. How it shakes out is yet to be seen, of course. The result could be even more siloing of content behind the walls of tech companies who want eyeballs and data to monetize on. I’d like to see something more akin to what Maciej wants. The web needs to “stay participatory.â€
But, even when the web was largely hypertext, it was’t all that participatory. Twenty years ago, the Internet was just starting to penetrate into ordinary people’s homes. The tipping point there was probably settling on the 56K Modem standard, and AOL opening up its walled garden to the Web at large. We were all going to connect in cyberspace over ISDN lines and something, something world peace. Really, most early adopters were more interested in drop shipping carpet, finding porn, or both.
At A Working Library, Mandy Brown is on to something in her great piece on Maciej’s talk.
“There’s an old saw about the web that says that when the web democratized publishing, everyone should have become a writer, but instead most of us became consumers. (Nevermind that email and SMS have most people writing more in a day than their Victorian ancestors wrote in their entire lives.)â€
Mandy’s seeing Maciej’s argument from the filter of a writer, and I’m seeing it from the filter of a writer and a web… site… making… guy. I don’t think the creator of a really awesome web bookmarking app is advocating we give up making cool applications that use the web as a platform. More that we people who make stuff on the web strip this crap down and focus on making awesome stuff everyone can use without compromising a user’s computing power or their privacy, and make it easier for someone to get started making that awesome stuff.
Which is going to be very, very hard for a lot of reasons, but laying those out will have to wait.
This is it. 2016 will finally be the Year of the Internet of Things, which is fast replacing the Year of Linux on the Desktop as a perennial fantasy tech prediction. Guaranteed, as CES comes to a head, every consumer technology company will show of some sort of connected home device. There will be a 500 word gadget blog piece on each. And they’ll either never reach the market, or summarily tank when they do. The optimism shall continue unabated, if only because there’s a still an untapped market of consumers with dumb, functional home devices that they’ll have to replace at some point, anyway.
Over at The Kernel, AJ Dellinger is cutting through some of the IoT nonsense, and he has some help from Nest CEO Tony Fadell of all people. The entire piece is well worth your time, but this is the big takeaway for the home:
When we think IoT, we think of things shown through the “smart house†trope, and companies already in the appliances business happily oblige the fantasy…
Sure, we have a ton of Internet-connected things, mostly RFID stuff for industrial applications. Home users are left with a frustrating, broken, insecure, and fragmented ecosystem of competing standards and platforms. There may be something to connected home stuff, though I remain skeptical. I’m unwilling to invest in expensive hardware to smarten up an apartment I might not be staying in for the long haul. Either way, the privacy and security aspects freak me right out. Let me cite Dillinger again:
These are billion-dollar industries that would love to be able to better target potential customers, and the data is floating around inside everyone’s homes. Google and Samsung, among others, are trying to capture it—and as interested as they are in selling it, they aren’t all that into the idea of sharing it.
And what the hell am I theoretically giving all that data up for? Aside from smart thermostats, nobody’s shown that potential in the home beyond a bunch of neat tricks with lightbulbs, and maybe having your phone go off when your food is finished cooking. (How is that easier than saying “Hey, Siri, set a timer for 30 minutes” to my Apple Watch, again?) It’s the data and insight into process that Internet connected sensors bring into our lives is valuable. That’s why advertisers want dibs on it. Dellinger seems to agree:
Businesses will continue to adopt the Internet of Things, and consumers will be able to benefit, whether by package-delivery notifications straight to their phones or sharing information from their Fitbits with their doctors. The $70 lightbulbs that connect to the Internet, though? They’re not going to be flying off the shelves.
Maybe I’m just missing something. I’ve been cynical about new product categories before. If anyone knows of a product that isn’t vaporware that has a quantifiable benefit over a non-computerized dumb appliance, I’d like to see it. Until someone comes up with the killer app for all of these expensive “smart” things they want to shove into my home, I’m going to remain skeptical.
Pop culture, especially for us socially isolated dorks, is an easy granfalloon to call our own. You have a ready-made conversation topic, a sense of purpose, and a way to identify the out-group. As a geek of the old school persuasion, I get it. Somewhere in my piles of stuff is a beat up, yellow paper card signifying that I am an official member of the Mystery Science Theater 3000 Information Club. It’ll be eighteen years, this year, since the day I got it in the mail from Minnesota. I have a similar, newer card, signifying my membership in Club DEVO, the DEVO Fan Club. That’s about the end of my formalized pop culture affiliations, though I have no shortage of informal ones—largely in music.
But these affiliations are starting to worry me. That worry is largely about the way online discourse occurs around pop culture. Especially when someone is critical of a particular piece of pop culture. You can’t say anything negative—or just counter to populist opinion—about something with a large, devoted fanbase in a public forum without raising the flaming ire of fans. Heaven forfend you make even a valid criticism, even of something you like, without being called out as a fake fan. And if you’re female, a person of color, or both, here come the rape threats.
Problems occur when the requirements to be part of the in-group increase. The more of a piece of pop culture you consume, the more trivia you can spout, more merchandise you can display, the truer a fan you are. For a new fan of anything, the requirements to join the in-group can become positively Sisyphean. And this is usually by design. It’s far from a new phenomenon, but the movement of pop culture from an interest to an identity has only amplified the territorial tendencies of geeks.
Which goes a long way towards why I’ve chosen to dial back from my geeky pop culture obsessions. I’m doing this in large part because I don’t like defining my identity based on someone else’s work, but also because I have seen the dark side of geeky obsession from both sides. Fandoms can become toxic, and it can happen on the turn of a dime. Just look at what happened recently in the Steven Universe fandom on Tumblr.